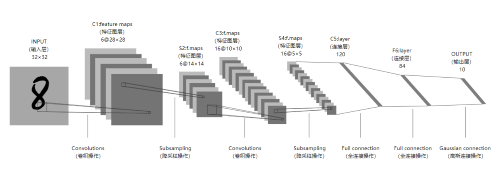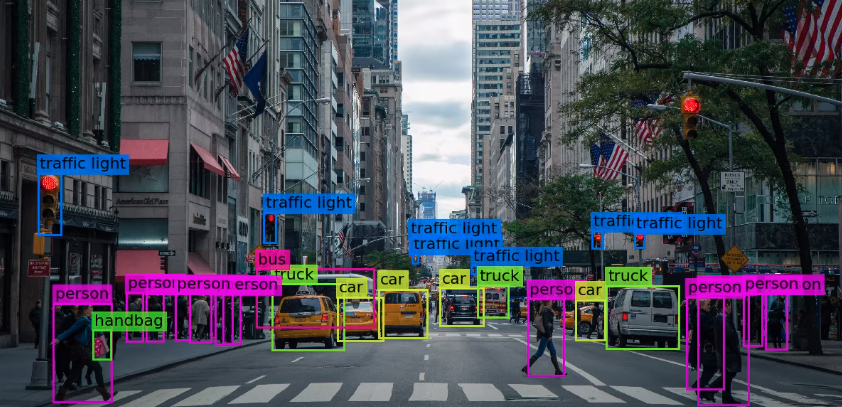
RF-DETR 是什么
RF-DETR 是一种基于实时目标检测 transformer 的架构,旨在很好地转移到各种领域以及大大小小的数据集。因此,RF-DETR 属于“DETR”(检测变压器)系列模型。它是为需要模型以高精度高速运行且通常在有限计算下(如边缘或低延迟)的项目开发的。

对比
我们相对于实时 COCO SOTA 变压器模型 (D-FINE, LW-DETR) 和 SOTA YOLO CNN 架构 (YOLO11, YOLOv8) 评估 RF-DETR。就这些参数而言,RF-DETR 是所有类别中唯一的模型 #1 或 #2。
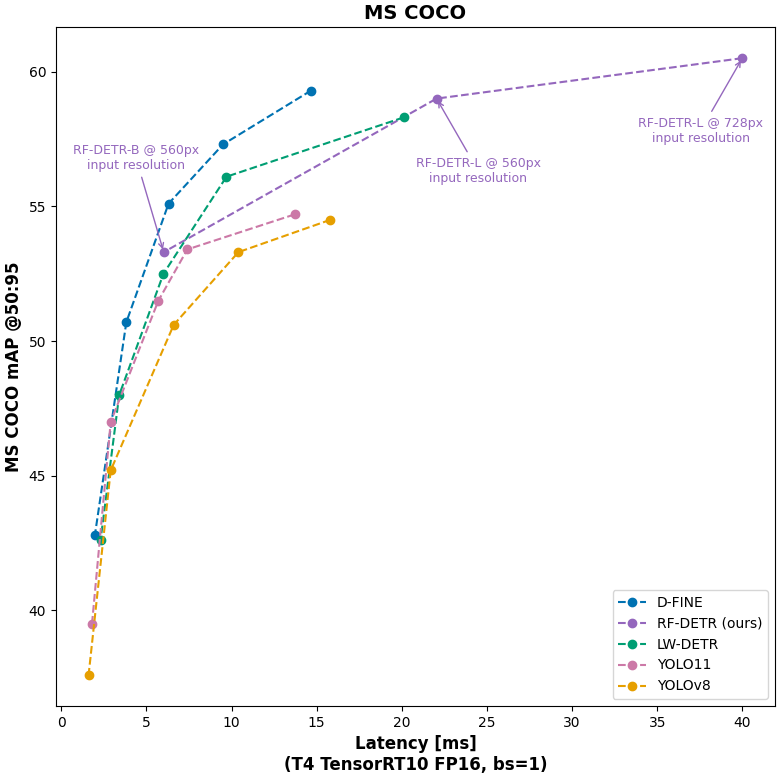
值得注意的是,显示的速度是使用 TensorRT10 FP16 (ms/img) 在 T4 上的 GPU 延迟,在 LW-DETR 推广的概念中称为 “总延迟 ”。与 transformer 模型不同,YOLO 模型执行 NMS 跟随模型预测,以提供候选边界框预测以提高准确性。
但是,NMS 会导致速度略有下降,因为边界框过滤需要计算(数量根据图像中的对象数量而变化)。请注意,大多数 YOLO 基准测试使用 NMS 来报告模型的准确性,但不包括 NMS 延迟来报告模型的相应速度。上述基准测试遵循 LW-DETR 的理念,即提供总时间来接收所有型号的同一台机器上统一应用的结果。与 LW-DETR 一样,我们使用经过调整的 NMS 来呈现延迟,旨在优化延迟,同时对准确性的影响最小。
其次,D-FINE 微调不可用,因此无法获得其域适应性。它的作者指出,“如果你的类别非常简单,它可能会导致过度拟合和次优的性能。还有许多悬而未决的问题阻碍了微调。我们打开了一个问题,旨在将 D-FINE 与 RF100-VL 进行基准测试。
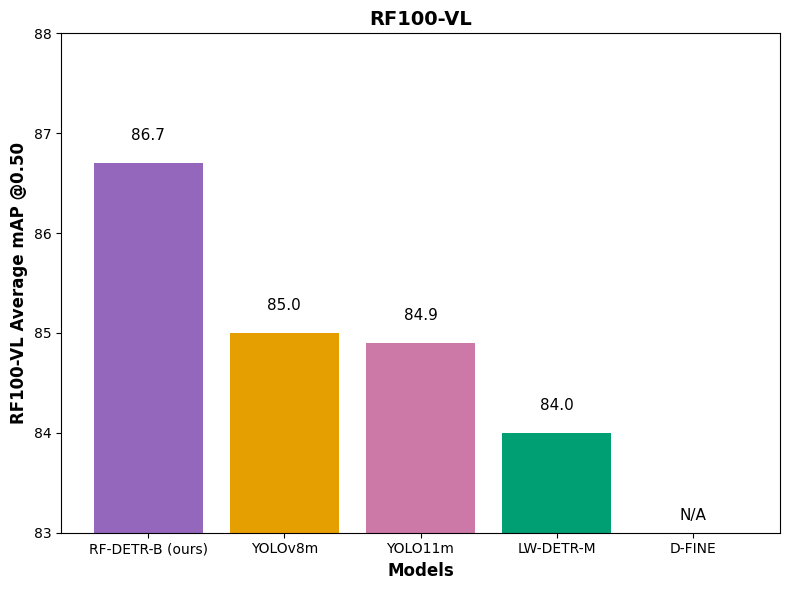
特别是在 COCO 上,RF-DETR 相对于 YOLO 模型严格来说是帕累托最优的,并且在基于实时变压器的模型方面具有竞争力 - 尽管严格来说不是更高性能。然而,在发布 RF-DETR-large 并使用 728 输入分辨率时,RF-DETR 实现了任何实时的最高 mAP (60.5)(Papers with Code 将“实时”定义为 T4 上的 25+ FPS)。
架构
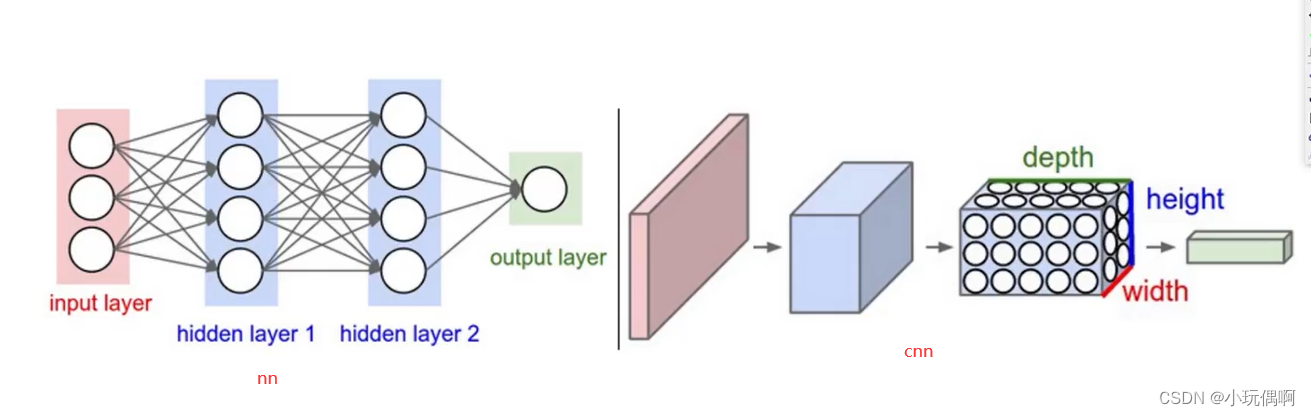
从历史上看,基于 CNN 的 YOLO 模型为实时对象检测器提供了最佳精度。CNN 仍然是计算机视觉中许多最佳方法的核心组成部分,例如 D-FINE 在其方法中同时利用 CNN 和 Transformer。
单独的 CNN 并不像基于 transformer 的方法那样从大规模预训练中受益,而且可能不太准确或收敛速度更慢。在机器学习的许多其他子领域中,从图像分类到 LLM,预训练对于获得强大的结果越来越重要。因此,从预训练中显示出强大优势的对象检测器可能会带来更好的对象检测结果。然而,变压器通常相当大且速度缓慢,不适合计算机视觉中的许多挑战。
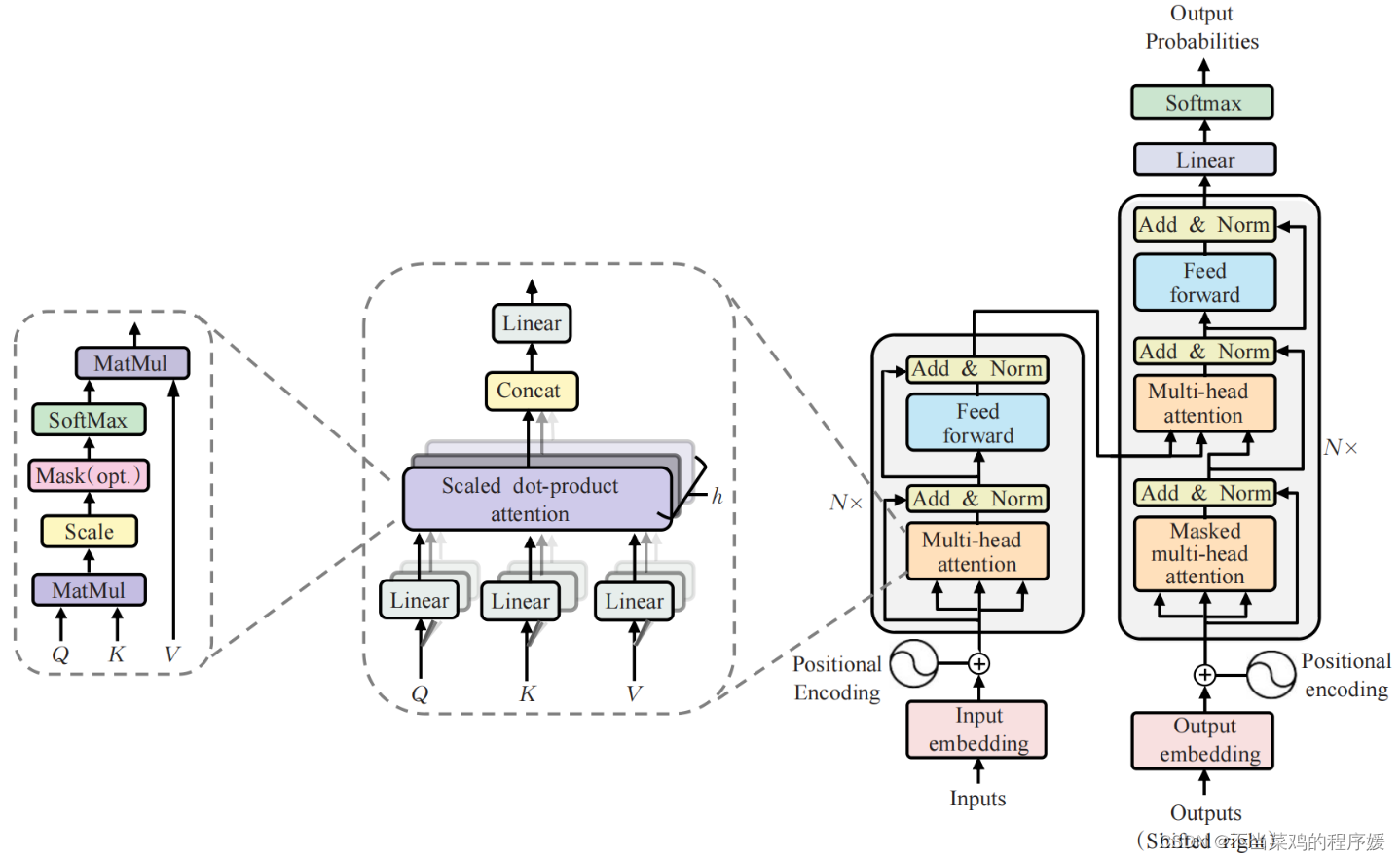
最近,通过在 2023 年引入 RT-DETR,在考虑 NMS 的运行时间时,DETR 系列模型已被证明在延迟方面与 YOLO 相匹配,这是 YOLO 模型而不是 DETR 所需的后处理步骤。此外,在使 DETR 快速融合方面,已经开展了大量工作。
DETR 的最新进展将这两个因素结合起来,创建了无需预训练即可与 YOLO 性能相匹配的模型,并且通过预训练,在给定的延迟下性能明显优于 YOLO。还有理由相信,更强的预训练可以提高模型从少量数据中学习的能力,这对于可能没有 COCO 规模数据集的任务非常重要。混合方法也在不断发展。YOLO-S 合并了 transformer 和 CNN 以实现实时性能。YOLOv12 还利用了 transformer 的序列学习。
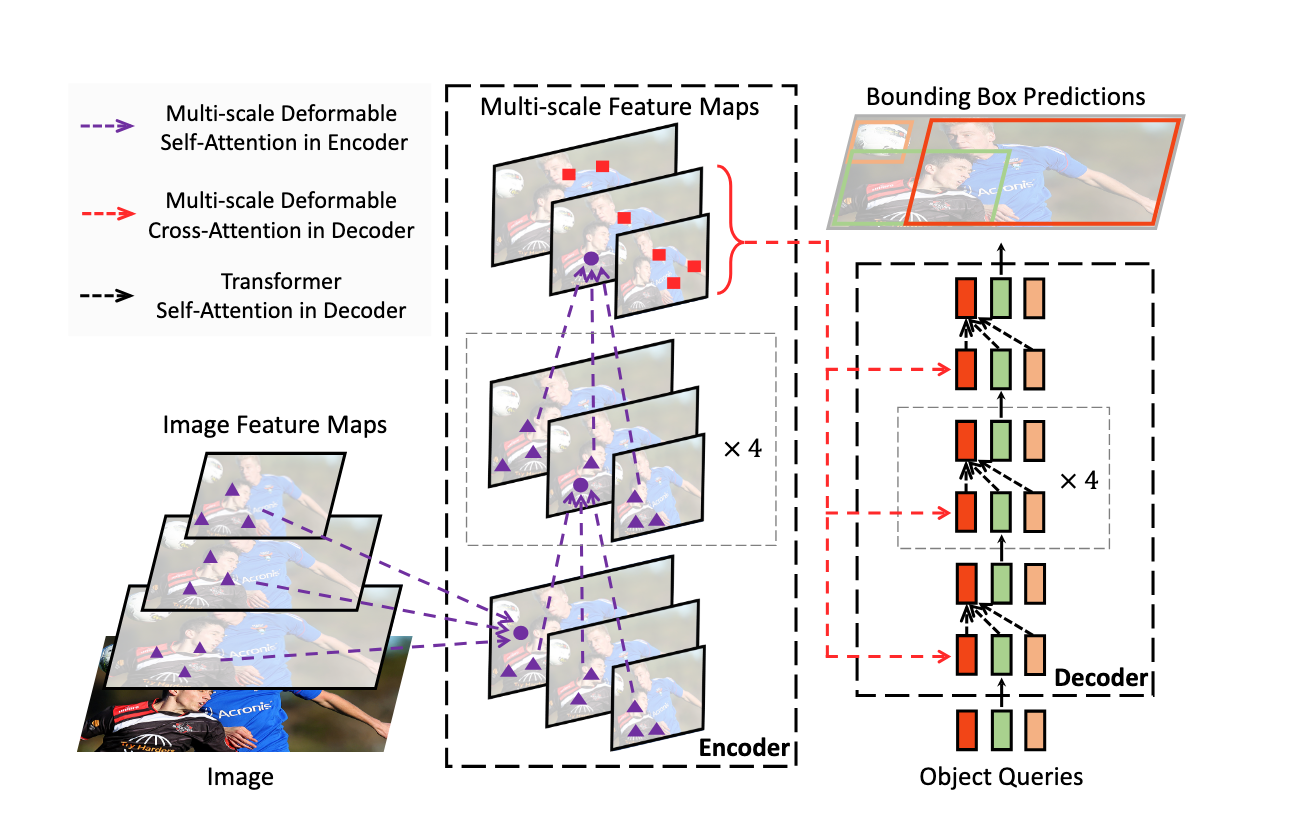
RF-DETR 使用的架构基于可变形 DETR 论文中的基础。Deformable DETR 使用多尺度自注意力机制,而我们从单尺度主干中提取图像特征图。
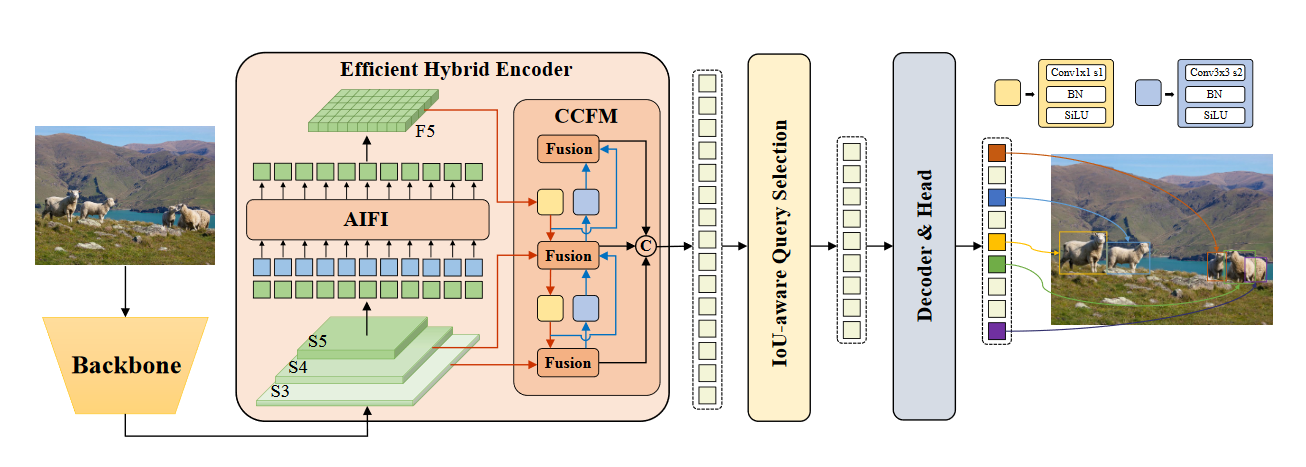
如何使用 RF-DETR
分成以下几个步骤
训练
数据集结构
RF-DETR 希望数据集为 COCO 格式。将数据集划分为三个子目录:train、valid 和 test。每个子目录都应该包含自己的文件,该文件包含该特定拆分的 Comments,以及相应的图像文件。下面是目录结构的示例:train valid test _annotations.coco.json
dataset/
├── train/
│ ├── _annotations.coco.json
│ ├── image1.jpg
│ ├── image2.jpg
├── valid/
│ ├── _annotations.coco.json
│ ├── image1.jpg
│ ├── image2.jpg
└── test/
├── _annotations.coco.json
├── image1.jpg
├── image2.jpgRoboflow 允许您从头开始创建对象检测数据集,或从 YOLO 等格式转换现有数据集,然后将其导出为 COCO JSON 格式进行训练。您还可以探索 Roboflow Universe 以查找适用于一系列使用案例的预标记数据集。
微调
您可以从预先训练的 COCO 检查点微调 RF-DETR。默认情况下,将使用 RF-DETR-B 检查点。要快速入门,请参阅我们的微调 Google Colab 笔记本。
from rfdetr import RFDETRBase
model = RFDETRBase()
model.train(dataset_dir=<DATASET_PATH>, epochs=10, batch_size=4, grad_accum_steps=4, lr=1e-4, output_dir=<OUTPUT_PATH>)不同的 GPU 具有不同的 VRAM 容量,因此请调整 batch_size 和 grad_accum_steps 以保持总批量大小为 16。例如,在像 A100 这样强大的 GPU 上,使用 和 ;在 T4 等较小的 GPU 上,使用 和 。这种梯度累积策略有助于在内存有限的情况下进行有效训练。batch_size=16 grad_accum_steps=1 batch_size=4 grad_accum_steps=4
恢复训练
您可以通过使用参数将路径传递给文件,从以前保存的检查点恢复训练。当训练中断或您想要继续微调已部分训练的模型时,这非常有用。训练循环将自动从提供的 checkpoint 文件中加载权重和优化器状态。checkpoint.pth resume
from rfdetr import RFDETRBase
model = RFDETRBase()
model.train(dataset_dir=<DATASET_PATH>, epochs=10, batch_size=4, grad_accum_steps=4, lr=1e-4, output_dir=<OUTPUT_PATH>, )早停
提前停止会监控验证 mAP,如果改进在设定的 epoch 数内仍低于阈值,则停止训练。这可以减少模型收敛后的计算浪费。其他参数(如 、 和 )允许您微调停止行为。early_stopping_patience early_stopping_min_delta early_stopping_use_ema
from rfdetr import RFDETRBase
model = RFDETRBase()
model.train(dataset_dir=<DATASET_PATH>, epochs=10, batch_size=4, grad_accum_steps=4, lr=1e-4, output_dir=<OUTPUT_PATH>, early_stopping=True)多 GPU 训练
您可以使用 PyTorch 的分布式数据并行 (DDP) 在多个 GPU 上微调 RF-DETR。创建一个脚本来初始化您的模型并像往常一样调用,而不是在终端中运行它。main.py .train()
python -m torch.distributed.launch --nproc_per_node=8 --use_env main.py替换为要使用的 GPU 数量。这种方法为每个 GPU 创建一个训练过程,并自动拆分工作负载。请注意,您的有效批量大小乘以 GPU 数量,因此您可能需要调整 和 以保持相同的总体批量大小。8 --nproc_per_node argument batch_size grad_accum_steps
结果检查点
在训练期间,两个模型检查点(常规权重和基于 EMA 的权重集)将保存在指定的输出目录中。EMA(指数移动平均线)文件是模型权重随时间变化的平滑版本,通常会产生更好的稳定性和泛化性。
预测
单图检测
以下代码展示了如何使用 RF-DETR 对单张图片进行目标检测。
import io
import requests
import supervision as sv
from PIL import Image
from rfdetr import RFDETRBase
from rfdetr.util.coco_classes import COCO_CLASSES
# 加载 RF-DETR 模型
model = RFDETRBase()
# 从 URL 加载图片
url = "https://media.roboflow.com/notebooks/examples/dog-2.jpeg"
image = Image.open(io.BytesIO(requests.get(url).content))
# 进行目标检测
detections = model.predict(image, threshold=0.5)
# 生成标注标签
labels = [
f"{COCO_CLASSES[class_id]} {confidence:.2f}"
for class_id, confidence
in zip(detections.class_id, detections.confidence)
]
# 绘制边界框和标签
annotated_image = image.copy()
annotated_image = sv.BoxAnnotator().annotate(annotated_image, detections)
annotated_image = sv.LabelAnnotator().annotate(annotated_image, detections, labels)
# 显示结果
sv.plot_image(annotated_image)视频检测
如果需要对视频进行推理,可以使用以下代码。
import supervision as sv
from rfdetr import RFDETRBase
from rfdetr.util.coco_classes import COCO_CLASSES
# 加载 RF-DETR 模型
model = RFDETRBase()
def callback(frame, index):
# 对每一帧进行目标检测
detections = model.predict(frame, threshold=0.5)
# 生成标注标签
labels = [
f"{COCO_CLASSES[class_id]} {confidence:.2f}"
for class_id, confidence
in zip(detections.class_id, detections.confidence)
]
# 绘制边界框和标签
annotated_frame = frame.copy()
annotated_frame = sv.BoxAnnotator().annotate(annotated_frame, detections)
annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
return annotated_frame
# 处理视频文件
process_video(
source_path="input_video.mp4", # Input video path
target_path="output_video.mp4", # Output video path
callback=callback
)
摄像头实时检测
您也可以通过摄像头实时进行目标检测。
import cv2
import supervision as sv
from rfdetr import RFDETRBase
from rfdetr.util.coco_classes import COCO_CLASSES
# 加载 RF-DETR 模型
model = RFDETRBase()
# 打开摄像头
cap = cv2.VideoCapture(0)
while True:
success, frame = cap.read()
if not success:
break
# 对每一帧进行目标检测
detections = model.predict(frame, threshold=0.5)
# 生成标注标签
labels = [
f"{COCO_CLASSES[class_id]} {confidence:.2f}"
for class_id, confidence
in zip(detections.class_id, detections.confidence)
]
# 绘制边界框和标签
annotated_frame = frame.copy()
annotated_frame = sv.BoxAnnotator().annotate(annotated_frame, detections)
annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
# 显示结果
cv2.imshow("Webcam", annotated_frame)
# 按下 'q' 键退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()